





En estos tiempos donde la Inteligencia Artificial (IA), Machine Learning (ML) y Deep Learning (DL) se ha convertido en el trampolín a la próxima generación de la tecnología, la implementación de procesos MLOps (Machine Learning Operations) es ahora en una pieza fundamental para llevar los modelos de aprendizaje automático desde la etapa de recolección de los datos hasta producción de manera eficiente y confiable.
En este artículo exploramos como implementar un proceso MLOps con AWS SageMaker utilizando Pytorch, unas de las bibliotecas de aprendizaje profundo más populares. A lo largo de esta guía, descubriremos las mejores prácticas y pasos clave para asegurarnos de que nuestros modelos de Pytorch sean escalables, reproducibles y gestionables en un entorno en la nube de AWS sin mucho código.
Ciclo de vida del ML
Desarrollar proyectos que produzcan capacidades inteligentes soportadas por ML, requiere de alguna metodología que marque las pautas a seguir durante su ciclo de vida del tratamiento de los datos. CRISP-ML(Q) (Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology) se ha convertido actualmente en una metodología referente a la hora de definir fases y pasos para diseñar procesos de MLOps.
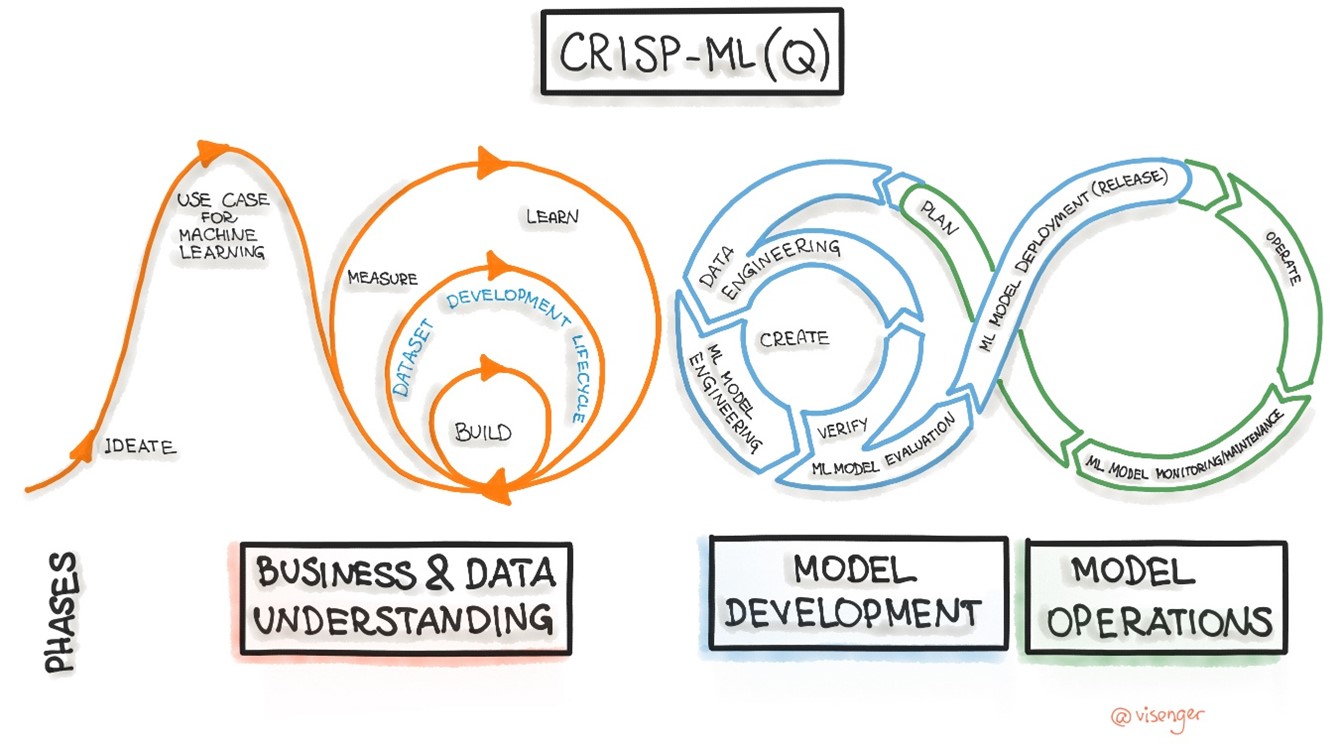
Esta metodología establece 6 fases, cada una con un grupo de pasos que se podrían implementar según el caso que corresponda.
- Entendimiento del problema y los datos.
- Ingeniería de los datos (Preparación de los datos).
- Ingeniería de ML
- Garantía de la calidad para aplicaciones ML.
- Despliegue
- Supervisión y mantenimiento.
Tratamiento de los datos
Las 2 primeras fases de la metodología CRISP-ML requieren identificar las fuentes de los datos, obtenerlos, analizarlos y prepararlos para las siguientes fases, es un momento importante del proceso de construcción de capacidades inteligentes, ya que requiere aplicar un conjunto de técnicas que mejoren y den valor a los datos que se serán usados más adelante. ETL es uno de los procesos más usados para abordar estas 2 primeras fases, y se compone en 3 subprocesos que define su nombre, Extracción, Transformación y Carga.
Los datos de origen pueden ser muy variados donde entran muchos factores a la hora de diseñar un proceso ETL, entre ellos tenemos el tipo de información, el formato, la cantidad y la sensibilidad. Dado que la carga de trabajo de mejorar los datos, entenderlo y poder sacarle el máximo provecho puede ser muy elevado y complejo, es importante conocer herramientas y plataformas que nos ayuden a facilitar y agilizar la implementación de los procesos ETL.
Las principales plataformas de nube como AWS, GPC, Azure o IBM, ofrecen desde hace varios años soluciones para cubrir esta necesidad, pero también existen de otras plataformas menos conocidas y más especializadas en esta área, que permiten a las empresas consolidar sus datos en Data Warehouse o Data Lakes, tales como Informática PowerCenter, Integrate.io, Domo, Stitch Data, entre otros.
ETL con AWS Glue Databrew
Glue es la herramienta bandera de AWS para implementar procesos ETL, que se apoya en otros servicios de la nube de Amazon para extender aún más las características de la herramienta. Aquí estaremos profundizando una extensión llamada Glue Databrew, que es el servicio serverless con interacción visual que permite crear y manejar cargas de trabajos relacionados con la mejora de la calidad de los datos. Cabe destacar que Glue Databrew se enfoca en el tratamiento de los datos más que la extracción de ellos, ya que dispone de una variedad de operaciones para leer datasets dentro de la nube de AWS pero pocas fuera de ella, por lo que para extraer datos de entornos on-premise o de cualquier otra plataforma se pueden usar servicios adicionales como, AWS DataSync, ETL AWS Glue, entre otros.
Para dar forma a un proceso de transformación de datos, debemos conocer algunos conceptos básicos que usa Databrew:
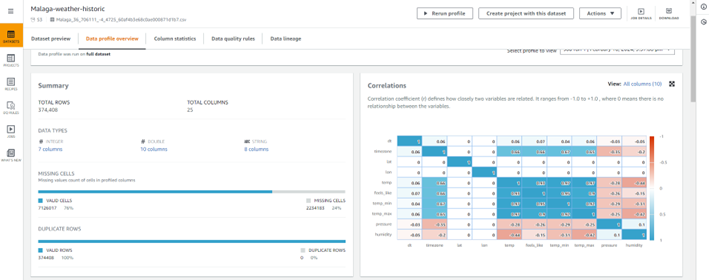
- Datasets: Son los datos de entrada que requieren ser transformados. Soporta formatos como CSV, Excel, Apache ORC, JSON y Apache Parquet. Esta pieza no solo identifica la ubicación de los datos, además muestra una previsualización de un subconjunto de ellos, y genera estadísticas útiles para comprender en un primer vistazo diferentes aspectos de los datos. En estas estadísticas podemos obtener el número total de filas y columnas, el porcentaje de valores válidos y ausentes, la tabla de correlación entre columnas, la distribución de los valores de cada columna incluyendo propiedades estadísticas como la media, moda, mediana, máximos, mínimo y la desviación estándar, valores atípicos, entre otros más.
- Projects: Es la pieza central de análisis y transformación de los datos, donde se unen los dataset con las recetas. Aquí se define un grupo de pasos para experimentar con distintos datasets y distintas recetas, y finalmente generar los Jobs que aplicará los pasos sobre los datos.
- Recipes: Es un inventario de acciones que se realizan sobre los datos del dataset. Existen más 250 recetas predefinidas en Databrew que se pueden usar, desde acciones simples como la limpieza de columnas o filas innecesarias, cambiar el nombre a columnas o añadir nuevas, hasta acciones más complejas como la binarización, cifrado de datos, normalización, One Hot Encoding, etc.
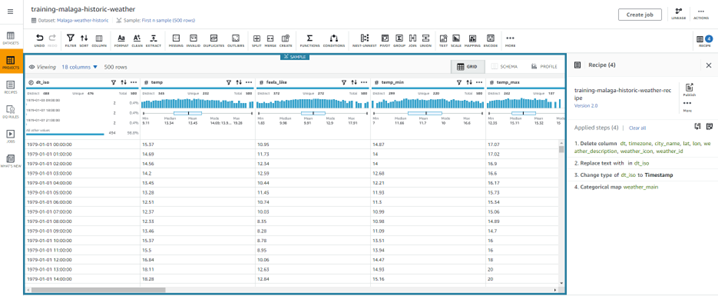
Las acciones que componen la transformación de datos también pueden ser configuradas en formato JSON o YAML. A continuación, un ejemplo de la configuración de las acciones de la imagen previa:
- Action:
Operation: DELETE
Parameters:
sourceColumns: >-
["dt","timezone","city_name","lat","lon","weather_description","weather_icon","weather_id"]
- Action:
Operation: REPLACE_TEXT
Parameters:
pattern: ' +0000 UTC'
sourceColumn: dt_iso
- Action:
Operation: CHANGE_DATA_TYPE
Parameters:
columnDataType: timestamp
replaceType: REPLACE_WITH_NULL
sourceColumn: dt_iso
- Action:
Operation: CATEGORICAL_MAPPING
Parameters:
categoryMap: >-
{"Clouds":"5","Clear":"1","Dust":"2","Rain":"7","Drizzle":"6","Haze":"3","Smoke":"4"}
deleteOtherRows: 'false'
keepOthers: 'true'
mapType: TEXT
mappingOption: ALL_VALUES
sourceColumn: weather_main
• targetColumn: weather_main_mapped
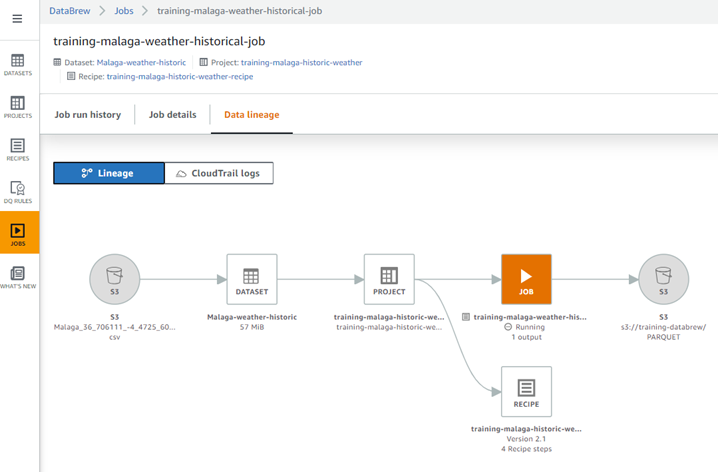
- Jobs: Esta es la pieza que consolida todas las configuraciones hechas en Datasets, Projects y Recipes, y ejecuta todos los pasos sobre para transformar los datos y construir un nuevo dataset que puede ser almacenado en diferentes servicios de almacenamiento de datos de AWS, por ejemplo, S3, Amazon Redshift, AWS Glue Data Catalog, y en plataformas externas como Snowflake, y también en distintos formatos como CSV, PARQUET, Apache ORC, Apache Avro, XML y JSON. Una vez creado el job, la herramienta nos permite observar el flujo que realiza para extraer los datos del dataset (E), aplicar las transformaciones de las recipes (T), y cargar el nuevo dataset en el destino (L).
Conclusión
Como vemos, es poca la dedicación que se requiere para implementar un proceso ETL sencillo, pero que podría generar mucha productividad a la hora de crear modelos de ML y automatizar los procesos de tratamientos de datos esenciales para los científicos de datos, sin embargo, todavía hay muchos más temas que podemos abordar en los procesos ETL, como el tratamiento de flujo de datos en streaming, incluir acciones de transformación personalizadas, complementar los datos con nuevos datasets, utilizar algoritmos de ML para mejorar la calidad de los datos, entre otro casos.
Las 2 primeras fases de la metodología CRISP-ML(Q) pueden llegar ocupar hasta el 80% del esfuerzo que se necesita para construir modelos de ML, por esta razón, es importante utilizar soluciones especializadas que nos permitan optimizar este tiempo que suele ser un poco tedioso para los científicos de datos, y así darle mayor foco a las siguientes fases que son igual de importantes.
Referencias
- Metodología CRISP-ML(Q): https://ml-ops.org/content/crisp-ml
- ETL: https://es.wikipedia.org/wiki/Extract,_transform_and_load
- AWS Glue Databrew: https://aws.amazon.com/es/glue/features/databrew/